Event-Driven Architectures for AI Agents: Why Request-Response Is Holding Your System Back
Your AI agents wait for instructions, execute, and return results. Meanwhile, the events they should be reacting to -- data changes, threshold breaches, upstream completions -- pass by unnoticed. Event-driven agent architectures flip the paradigm from polling to reacting.
The Synchronous Trap
Most production AI agent systems follow the same interaction pattern: something triggers a request, the agent processes it, and returns a response. User asks a question, agent answers. API call arrives, agent generates output. Cron job fires, agent runs a batch. Request in, response out.
This works. It also leaves enormous value on the table.
The fundamental limitation of request-response agent architectures is that agents only act when explicitly asked. They are passive by default. In a world where the data they need to reason about is constantly changing -- new records in databases, price movements in markets, sensor readings from equipment, deployments in CI/CD pipelines -- waiting for a request means missing the window where action would have been most valuable.
Event-driven architectures solve this by inverting the control flow. Instead of agents waiting for requests, events flow to agents that have declared interest in specific signals. The agent does not poll for changes. Changes find the agent. This is not a theoretical distinction. It is the difference between an agent that detects a production anomaly when someone asks "is anything wrong" and an agent that detects the anomaly the moment the metrics deviate -- potentially minutes or hours before anyone thinks to ask.
The engineering challenge is that event-driven agent systems are significantly harder to build, debug, and operate than request-response systems. The patterns that make them reliable in production are not obvious, and most teams learn them the hard way.
Why Request-Response Agents Hit a Ceiling
Request-response agent architectures have three structural limitations that become acute as systems scale.
First, latency compounds across multi-step workflows. When Agent A needs output from Agent B, which needs output from Agent C, you are stacking synchronous calls. Each hop adds network latency, inference latency, and queuing latency. A four-agent chain with 2-second average per-agent latency takes 8 seconds end-to-end before the user sees anything. As we explored in our analysis of latency budgets for AI pipelines, most real-time use cases have a 3-5 second total budget. Synchronous multi-agent chains blow through that budget by design.
Second, request-response creates tight coupling between agents. Agent A needs to know Agent B exists, know its API contract, handle its failures, and retry its timeouts. When you have twenty agents in a system, the coupling matrix becomes unmanageable. Adding a new agent requires updating every agent that might need its output. This is the same distributed monolith problem that drove microservices teams toward event-driven architectures a decade ago -- and the same solution applies.
Third, synchronous architectures waste compute on polling. If Agent A needs to react when a database table changes, the request-response approach is to poll: check the table every N seconds, see if anything changed, act if it did. This is wasteful, introduces latency equal to half the polling interval on average, and scales poorly. Ten agents polling ten data sources at one-second intervals is a hundred database queries per second that return "nothing changed" 99% of the time.
The Event-Driven Agent Architecture
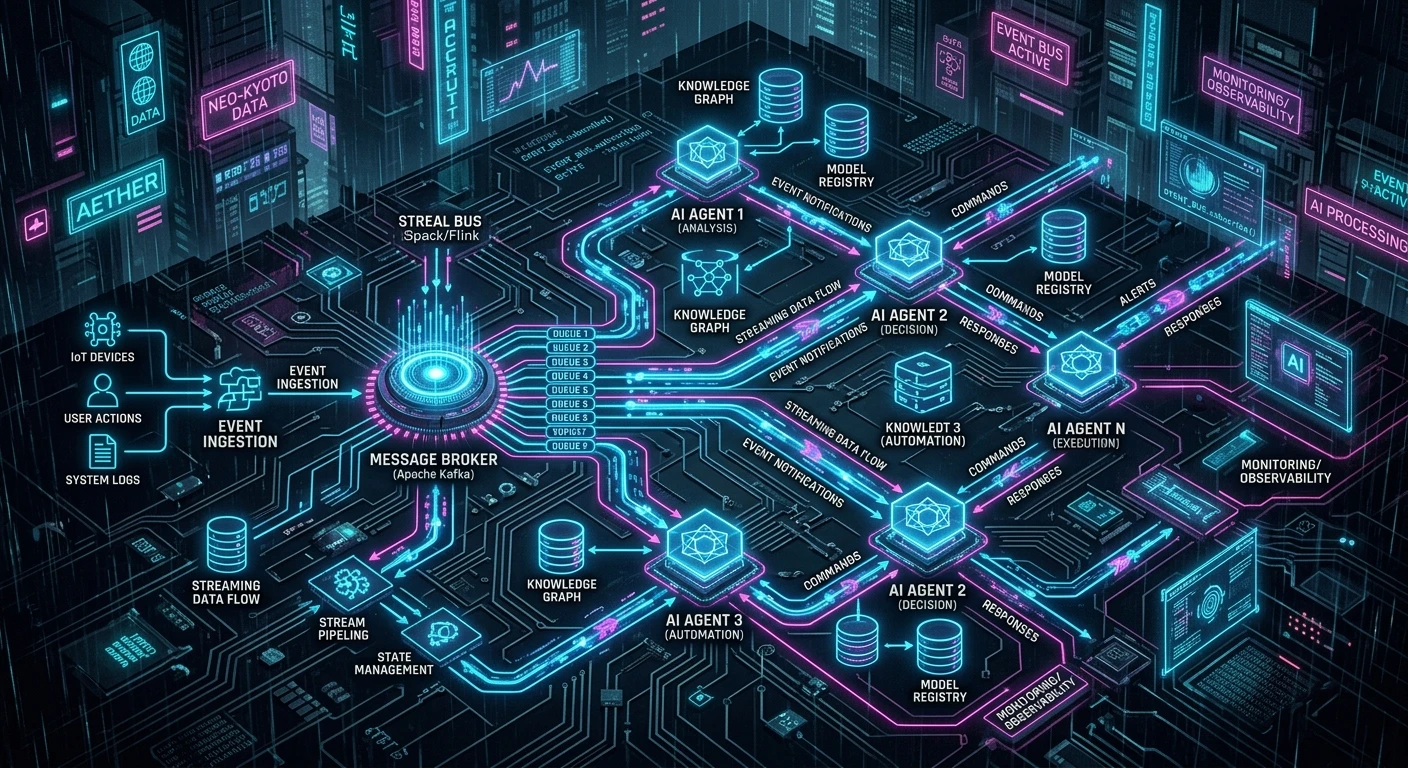
An event-driven agent system has four core components: event sources, an event bus, agent subscriptions, and a state store.
Event sources emit signals when something changes. A database emits change data capture (CDC) events. An API gateway emits request events. A monitoring system emits metric threshold events. A CI/CD pipeline emits deployment events. The key design principle is that event sources do not know which agents -- if any -- will consume their events. They publish facts about what happened. They do not address messages to specific recipients.
The event bus routes events to interested agents. Kafka, Pulsar, NATS, or cloud-native equivalents (EventBridge, Pub/Sub) serve this role. The bus provides ordering guarantees, durability, and fan-out -- one event can trigger multiple agents simultaneously without the source knowing or caring. This is where the coupling breaks: agents depend on event schemas, not on each other.
Agent subscriptions declare which events an agent cares about. A fraud detection agent subscribes to transaction events. A content moderation agent subscribes to upload events. A cost engineering agent subscribes to inference billing events. Subscriptions can be simple (all events of type X) or filtered (events of type X where amount > threshold). The subscription model means adding a new agent requires zero changes to existing agents -- you just add a new subscriber.
The state store maintains agent memory across events. This is where event-driven agent architectures diverge from traditional event-driven microservices. Agents need context. A fraud detection agent that receives a transaction event needs to know the customer's transaction history, risk profile, and recent behavior. Stateless architectures are a dead end for enterprise agents -- the state store is what transforms a reactive function into an intelligent agent.
Production Patterns That Work
Event Sourcing for Agent Decisions
Store every event that influenced an agent's decision, not just the decision itself. When the fraud agent flags a transaction, record the triggering event, the context events it retrieved from the state store, the reasoning chain, and the output. This creates a complete audit trail that regulators and internal reviewers can walk through. It also enables replay: if the agent's model is updated, you can replay historical event sequences to see how decisions would have changed.
Saga Pattern for Multi-Agent Workflows
When a business process requires multiple agents to act in sequence -- say, document extraction followed by validation followed by routing followed by notification -- use the saga pattern. Each agent completes its step and emits a completion event. The next agent subscribes to that completion event. If any step fails, compensating events trigger rollback actions. This replaces the fragile orchestrator that calls agents synchronously and hopes none of them time out.
The saga pattern works particularly well with deterministic control planes that enforce hard boundaries on what each agent can do. The control plane validates events against allowed transitions, preventing agents from triggering actions outside their authorized scope.
Dead Letter Queues for Agent Failures
Agents fail. Models hallucinate, context windows overflow, rate limits hit, dependencies go down. In a request-response system, failures propagate immediately -- the caller gets an error. In an event-driven system, failures are silent unless you plan for them. Dead letter queues capture events that agents failed to process. A monitoring agent watches the dead letter queue and triggers alerts, retries, or human escalation based on failure patterns.
Event Filtering and Enrichment
Not every event deserves a full LLM inference call. An event enrichment layer sits between the bus and agent subscriptions, adding context from the state store and filtering low-value events before they reach agents. A customer support agent does not need to process every page view event -- it needs page view events where the customer has an open support ticket and has visited the help center more than three times in the last hour. The enrichment layer makes this determination cheaply, preserving expensive inference capacity for events that actually warrant agent attention.
The Hybrid Architecture
Pure event-driven agent systems are elegant in theory and painful in practice for certain use cases. Interactive conversations, real-time Q&A, and synchronous API integrations genuinely need request-response semantics. Forcing them through an event bus adds latency and complexity without benefit.
The production pattern that works is a hybrid: request-response for synchronous interactions, event-driven for reactive intelligence. The same agent can have both a synchronous API endpoint (for user-facing queries) and event subscriptions (for background monitoring). The agent's state store serves both paths, so the agent answering a user's synchronous question has full context from events it processed asynchronously.
This hybrid model is how multi-agent orchestration systems that survive real traffic actually work. The orchestrator handles synchronous flows. The event bus handles asynchronous intelligence. The two meet at the state store.
Implementation Realities
Three things will bite you when building event-driven agent systems.
First, event schema evolution is hard. When you change the schema of a transaction event, every agent that subscribes to transaction events needs to handle both the old and new schema. In request-response systems, you version APIs. In event-driven systems, you version event schemas -- and unlike APIs, you cannot force consumers to upgrade because you may not even know who they are. Use schema registries (Confluent Schema Registry, AWS Glue Schema Registry) and default to backward-compatible changes.
Second, debugging distributed event flows is miserable without proper tooling. When a user reports that the system did not react to a data change, you need to trace the event from source through the bus to the subscribing agent, check the enrichment layer, verify the subscription filter, inspect the agent's state at the time of processing, and review the agent's reasoning. Observability for AI systems is already harder than traditional APM. Event-driven architectures multiply that complexity. Invest in distributed tracing (OpenTelemetry with correlation IDs propagated through events) before you need it.
Third, exactly-once processing is a myth in distributed systems. Events will occasionally be delivered twice. Agents must be idempotent -- processing the same event twice should produce the same result as processing it once. For LLM-based agents, this means caching decisions keyed by event ID and returning the cached result on duplicate delivery rather than running inference again.
When to Make the Switch
Not every agent system needs event-driven architecture. If your agents only respond to direct user queries and do not need to react to environmental changes, request-response is simpler and sufficient.
Event-driven architecture becomes necessary when: agents need to react to data changes in real-time; multiple agents need to respond to the same trigger independently; agent workflows span more than three sequential steps; the system needs to scale agent count without increasing coupling; or audit and replay requirements demand a complete event history.
The migration path is incremental. Start by putting an event bus between your most coupled agents. Move one workflow from synchronous orchestration to saga-based choreography. Add event sourcing to your most audited agent decisions. Each step delivers value independently and reduces the risk of a big-bang migration.
The agents that will define enterprise AI in the next two years are not the ones with the best models. They are the ones that react to the right signals at the right time. Event-driven architecture is how you build systems that do not wait to be asked.
Founder & Principal Architect
Ready to explore AI for your organization?
Schedule a free consultation to discuss your AI goals and challenges.
Book Free Consultation