Hot-Swap Model Routing in Production: Engineering Model Failover Without Downtime
Your primary model provider has an outage. Your users experience it as a product failure. Hot-swap routing eliminates this single point of failure by treating model providers as interchangeable backends behind an intelligent routing layer.
The Single Provider Problem
Every production AI system starts the same way: you pick a model provider, wire it in, ship it. OpenAI, Anthropic, Google -- does not matter. What matters is that you now have a single point of failure masquerading as a strategic choice.
When that provider has an outage -- and they all do -- your product goes down. Not because your code is broken. Not because your infrastructure failed. Because you made an architectural decision that equates "model" with "provider" and treats them as inseparable.
Hot-swap model routing separates these concerns. It treats model providers as interchangeable backends behind a routing layer that can redirect traffic in milliseconds without user-visible degradation.
Why This Is Harder Than Load Balancing
The naive response is "just add a fallback." But model routing is not HTTP load balancing. The challenges are unique:
Output consistency. Different models produce different outputs for identical inputs. If your system routes from Claude to GPT-4 mid-conversation, the user experiences a personality shift. Your downstream parsers may break because output formats diverge.
Capability asymmetry. Not all models support the same features. Tool use, structured output, vision, long context -- your routing layer must understand capability matrices, not just availability.
Cost differentials. Failing over from a $3/M-token model to a $15/M-token model during an outage can 5x your costs in minutes. The routing layer needs cost awareness, not just availability awareness.
Latency profiles. Different providers have different latency characteristics. A failover that doubles response time may be worse than a brief outage for real-time applications.
These constraints mean hot-swap routing requires an abstraction layer that normalizes not just the API interface but the behavioral characteristics of each backend. This is compound AI system orchestration applied to the infrastructure layer.
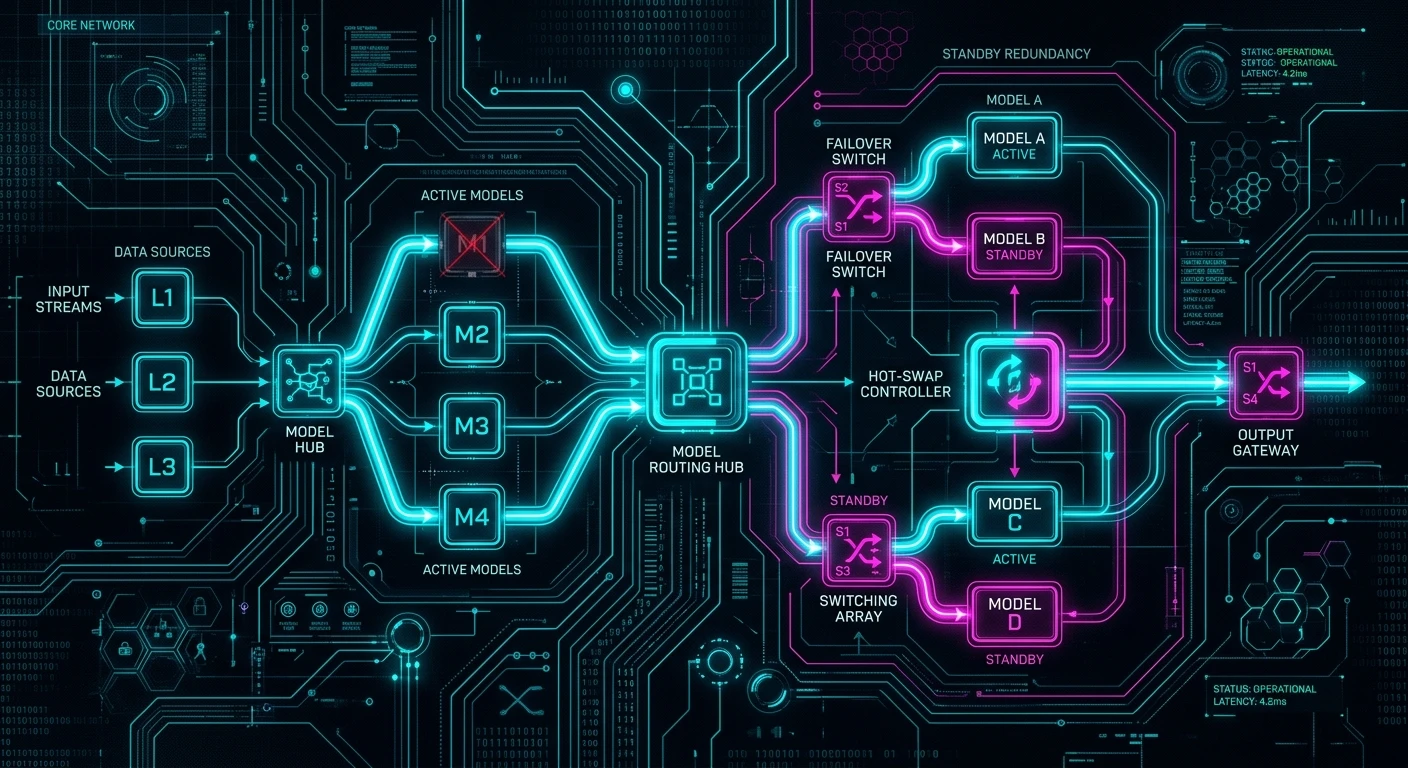
The Architecture Pattern
Production hot-swap routing has four components:
1. The Provider Abstraction Layer
Every model provider gets wrapped in a normalized interface. Request format, response format, error codes, streaming behavior -- all normalized. This is not just an SDK wrapper. It includes output post-processing to ensure behavioral consistency across providers.
The abstraction must handle: authentication, rate limits, retry policies, timeout behavior, and streaming semantics that differ wildly across providers.
2. The Health Monitor
Continuous health checking against each provider. Not just "is the API responding" but "is the API responding with acceptable quality." This means:
- Latency percentile tracking (p50, p95, p99)
- Error rate monitoring (4xx vs 5xx vs timeout)
- Quality sampling (periodic eval requests to detect degradation)
- Cost tracking (detecting pricing changes or unexpected token consumption)
The health monitor feeds the routing decision engine with real-time provider state. This connects directly to the principles of observability for AI systems -- you cannot route intelligently without comprehensive telemetry.
3. The Routing Decision Engine
This is where the intelligence lives. The router considers:
- Current provider health scores
- Request characteristics (does this request need vision? long context? tool use?)
- Cost constraints (budget remaining, cost-per-request limits)
- Consistency requirements (is this a continued conversation that should stay on the same provider?)
- Load distribution targets (spreading traffic to maintain warm connections across providers)
The simplest version is priority-based failover: try Provider A, fall back to Provider B, then C. Production systems need more sophistication: weighted routing, capability-based selection, and session affinity with graceful migration.
4. The Consistency Layer
The hardest problem. When you route a request to a different provider, you need output consistency. This means:
- System prompt adaptation (each model responds differently to the same prompt -- you need provider-specific prompt variants)
- Output normalization (structured output schemas may need per-provider extraction logic)
- Conversation continuity (translating conversation history into provider-specific formats)
- Behavioral calibration (temperature and sampling parameters mean different things across providers)
Implementation: The Shadow Traffic Pattern
The safest way to build confidence in your routing layer is shadow traffic. Before enabling failover, route a percentage of production requests to your secondary provider in shadow mode -- execute the request but discard the response. This gives you:
- Real production latency data for the secondary provider
- Output quality comparison data
- Cost projections based on actual traffic patterns
- Confidence that the failover path works before you need it
Shadow traffic is expensive -- you are paying for requests you throw away. But it is dramatically cheaper than discovering your failover is broken during an actual outage. This is the same philosophy behind feature flags for AI model rollout: validate in production before committing.
The Sticky Session Problem
Multi-turn conversations create a routing constraint: switching providers mid-conversation degrades experience. But provider outages do not wait for conversations to end.
The solution is tiered affinity:
- Hard affinity: Never switch mid-conversation (accept downtime for active sessions)
- Soft affinity: Prefer the same provider but allow switching with a transition prompt that re-establishes context
- No affinity: Every request routes independently (only works for stateless, single-turn interactions)
Most production systems use soft affinity with a transition strategy: when a failover occurs mid-conversation, inject a hidden system message that summarizes the conversation state for the new provider. Users experience a brief pause, not a failure.
Cost Engineering the Routing Layer
Smart routing is also a cost optimization lever. During normal operations -- when all providers are healthy -- you can route based on cost-performance tradeoffs:
- Simple classification tasks go to the cheapest provider that meets quality thresholds
- Complex reasoning tasks go to the most capable provider regardless of cost
- Batch processing routes to providers with favorable batch pricing
- Real-time requests route to the lowest-latency provider
This transforms the routing layer from a reliability mechanism into a cost engineering tool. Teams we work with typically see 20-35% cost reduction from intelligent routing alone, before accounting for the reliability benefits.
What Goes Wrong
Cascading failover storms. Provider A goes down. All traffic shifts to Provider B. Provider B cannot handle 2x traffic and starts failing. Now you have lost both providers. Solution: gradual traffic shifting with backpressure, not instant cutover.
Stale health data. Your health monitor says Provider A is healthy, but it went down 30 seconds ago and your check interval is 60 seconds. Solution: circuit breakers that trip on inline request failures, not just scheduled health checks.
Configuration drift between providers. You update the system prompt for Provider A but forget to update the Provider B variant. Failover produces subtly wrong behavior that takes days to notice. Solution: configuration management that treats all provider variants as a single deployable unit.
Testing only the happy path. You test that failover works when Provider A returns 500s. You do not test what happens when Provider A returns 200s with garbage content (quality degradation without explicit errors). Solution: quality-aware health monitoring that samples and evaluates actual outputs.
This connects to the broader challenge of configuration drift in AI systems -- multi-provider setups multiply the surface area for drift.
The Organizational Pattern
Hot-swap routing is not just an engineering pattern. It is an organizational capability. It requires:
- Multi-provider contracts -- you need active accounts with at least two providers at all times
- Continuous evaluation -- regular benchmarking of all providers against your specific use cases
- Runbook documentation -- what to do when the routing layer itself fails
- Cost modeling -- understanding the cost implications of different routing scenarios
Teams that treat provider selection as a one-time decision instead of an ongoing routing optimization are building fragile systems. The model landscape changes monthly. New providers emerge, existing providers change pricing, capabilities shift. Your routing layer should adapt continuously.
Building It Today
Start with the minimum viable routing layer:
- Abstract your model calls behind a unified interface
- Add a second provider with capability parity for your primary use case
- Implement basic health checking and manual failover
- Add automated failover with circuit breaker semantics
- Graduate to intelligent routing based on cost, latency, and quality signals
Each step delivers immediate value. Step 1 alone makes your codebase provider-agnostic. Step 3 means you can survive an outage with a single configuration change. Step 5 optimizes cost and performance continuously.
The teams building production AI systems that survive real-world conditions treat model routing as infrastructure, not application logic. It belongs in the platform layer, maintained by the team that owns reliability.
The Bottom Line
Every production AI system will experience a model provider outage. The only question is whether your architecture treats that as a catastrophe or a routine infrastructure event. Hot-swap routing makes it the latter.
The investment is modest -- a few weeks of engineering for the basic pattern. The payoff is eliminating an entire class of production incidents while simultaneously enabling cost optimization and performance tuning. There is no good reason to run production AI on a single provider in 2026.
Need help architecting model routing for your production AI system? Book a session to discuss your specific reliability and cost requirements.
Founder & Principal Architect
Ready to explore AI for your organization?
Schedule a free consultation to discuss your AI goals and challenges.
Book Free Consultation